Airflow Integration
If you're looking to schedule DataHub ingestion using Airflow, see the guide on scheduling ingestion with Airflow.
The DataHub Airflow plugin supports:
- Automatic column-level lineage extraction from various operators e.g. SQL operators (including
MySqlOperator,PostgresOperator,SnowflakeOperator,BigQueryInsertJobOperator, and more),S3FileTransformOperator, and more. - Airflow DAG and tasks, including properties, ownership, and tags.
- Task run information, including task successes and failures.
- Manual lineage annotations using
inletsandoutletson Airflow operators.
There's two implementations of the plugin, with different Airflow version support.
| Approach | Airflow Versions | Notes |
|---|---|---|
| Plugin v2 | 2.3.4+ | Recommended. Requires Python 3.8+ |
| Plugin v1 | 2.3 - 2.8 | Deprecated. No automatic lineage extraction; may not extract lineage if the task fails. |
If you're using Airflow older than 2.3, it's possible to use the v1 plugin with older versions of acryl-datahub-airflow-plugin. See the compatibility section for more details.
DataHub Plugin v2
Installation
The v2 plugin requires Airflow 2.3+ and Python 3.8+. If you don't meet these requirements, see the compatibility section for other options.
pip install 'acryl-datahub-airflow-plugin[plugin-v2]'
Configuration
Set up a DataHub connection in Airflow, either via command line or the Airflow UI.
Command Line
airflow connections add --conn-type 'datahub-rest' 'datahub_rest_default' --conn-host 'http://datahub-gms:8080' --conn-password '<optional datahub auth token>'
If you are using DataHub Cloud then please use https://YOUR_PREFIX.acryl.io/gms as the --conn-host parameter.
Airflow UI
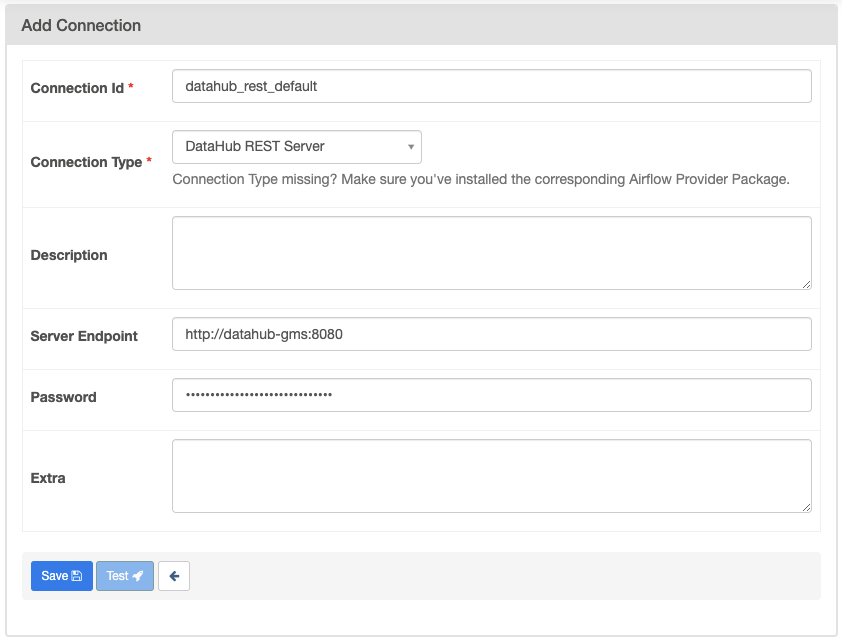
On the Airflow UI, go to Admin -> Connections and click the "+" symbol to create a new connection. Select "DataHub REST Server" from the dropdown for "Connection Type" and enter the appropriate values.
Optional Configurations
No additional configuration is required to use the plugin. However, there are some optional configuration parameters that can be set in the airflow.cfg file.
[datahub]
# Optional - additional config here.
enabled = True # default
| Name | Default value | Description |
|---|---|---|
| enabled | true | If the plugin should be enabled. |
| conn_id | datahub_rest_default | The name of the datahub rest connection. |
| cluster | prod | name of the airflow cluster, this is equivalent to the env of the instance |
| capture_ownership_info | true | Extract DAG ownership. |
| capture_ownership_as_group | false | When extracting DAG ownership, treat DAG owner as a group rather than a user |
| capture_tags_info | true | Extract DAG tags. |
| capture_executions | true | Extract task runs and success/failure statuses. This will show up in DataHub "Runs" tab. |
| materialize_iolets | true | Create or un-soft-delete all entities referenced in lineage. |
| enable_extractors | true | Enable automatic lineage extraction. |
| disable_openlineage_plugin | true | Disable the OpenLineage plugin to avoid duplicative processing. |
| log_level | no change | [debug] Set the log level for the plugin. |
| debug_emitter | false | [debug] If true, the plugin will log the emitted events. |
DataHub Plugin v1
Installation
The v1 plugin requires Airflow 2.3 - 2.8 and Python 3.8+. If you're on older versions, it's still possible to use an older version of the plugin. See the compatibility section for more details.
Note that the v1 plugin is less featureful than the v2 plugin, and is overall not actively maintained.
Since datahub v0.15.0, the v2 plugin has been the default. If you need to use the v1 plugin with acryl-datahub-airflow-plugin v0.15.0+, you must also set the environment variable DATAHUB_AIRFLOW_PLUGIN_USE_V1_PLUGIN=true.
pip install 'acryl-datahub-airflow-plugin[plugin-v1]'
# The DataHub rest connection type is included by default.
# To use the DataHub Kafka connection type, install the plugin with the kafka extras.
pip install 'acryl-datahub-airflow-plugin[plugin-v1,datahub-kafka]'
Configuration
Disable lazy plugin loading
[core]
lazy_load_plugins = False
On MWAA you should add this config to your Apache Airflow configuration options.
Setup a DataHub connection
You must configure an Airflow connection for Datahub. We support both a Datahub REST and a Kafka-based connections, but you only need one.
# For REST-based:
airflow connections add --conn-type 'datahub_rest' 'datahub_rest_default' --conn-host 'http://datahub-gms:8080' --conn-password '<optional datahub auth token>'
# For Kafka-based (standard Kafka sink config can be passed via extras):
airflow connections add --conn-type 'datahub_kafka' 'datahub_kafka_default' --conn-host 'broker:9092' --conn-extra '{}'
Configure the plugin
If your config doesn't align with the default values, you can configure the plugin in your airflow.cfg file.
[datahub]
enabled = true
conn_id = datahub_rest_default # or datahub_kafka_default
# etc.
| Name | Default value | Description |
|---|---|---|
| enabled | true | If the plugin should be enabled. |
| conn_id | datahub_rest_default | The name of the datahub connection you set in step 1. |
| cluster | prod | name of the airflow cluster |
| capture_ownership_info | true | If true, the owners field of the DAG will be capture as a DataHub corpuser. |
| capture_ownership_as_group | false | When extracting DAG ownership, treat DAG owner as a group rather than a user. |
| capture_tags_info | true | If true, the tags field of the DAG will be captured as DataHub tags. |
| capture_executions | true | If true, we'll capture task runs in DataHub in addition to DAG definitions. |
| materialize_iolets | true | Create or un-soft-delete all entities referenced in lineage. |
| render_templates | true | If true, jinja-templated fields will be automatically rendered to improve the accuracy of SQL statement extraction. |
| datajob_url_link | taskinstance | If taskinstance, the datajob url will be taskinstance link on airflow. It can also be grid. |
| graceful_exceptions | true | If set to true, most runtime errors in the lineage backend will be suppressed and will not cause the overall task to fail. Note that configuration issues will still throw exceptions. |
| dag_filter_str | { "allow": [".*"] } | AllowDenyPattern value in form of JSON string to filter the DAGs from running. |
Validate that the plugin is working
- Go and check in Airflow at Admin -> Plugins menu if you can see the DataHub plugin
- Run an Airflow DAG. In the task logs, you should see Datahub related log messages like:
Emitting DataHub ...
Automatic lineage extraction
Only the v2 plugin supports automatic lineage extraction. If you're using the v1 plugin, you must use manual lineage annotation or emit lineage directly.
To automatically extract lineage information, the v2 plugin builds on top of Airflow's built-in OpenLineage extractors. As such, we support a superset of the default operators that Airflow/OpenLineage supports.
The SQL-related extractors have been updated to use DataHub's SQL lineage parser, which is more robust than the built-in one and uses DataHub's metadata information to generate column-level lineage.
Supported operators:
SQLExecuteQueryOperator, including any subclasses. Note that in newer versions of Airflow (generally Airflow 2.5+), most SQL operators inherit from this class.AthenaOperatorandAWSAthenaOperatorBigQueryOperatorandBigQueryExecuteQueryOperatorBigQueryInsertJobOperator(incubating)MySqlOperatorPostgresOperatorRedshiftSQLOperatorSnowflakeOperatorandSnowflakeOperatorAsyncSqliteOperatorTrinoOperator
Known limitations:
- We do not fully support operators that run multiple SQL statements at once. In these cases, we'll only capture lineage from the first SQL statement.
Manual Lineage Annotation
Using inlets and outlets
You can manually annotate lineage by setting inlets and outlets on your Airflow operators. This is useful if you're using an operator that doesn't support automatic lineage extraction, or if you want to override the automatic lineage extraction.
We have a few code samples that demonstrate how to use inlets and outlets:
For more information, take a look at the Airflow lineage docs.
Custom Operators
If you have created a custom Airflow operator that inherits from the BaseOperator class,
when overriding the execute function, set inlets and outlets via context['ti'].task.inlets and context['ti'].task.outlets.
The DataHub Airflow plugin will then pick up those inlets and outlets after the task runs.
class DbtOperator(BaseOperator):
...
def execute(self, context):
# do something
inlets, outlets = self._get_lineage()
# inlets/outlets are lists of either datahub_airflow_plugin.entities.Dataset or datahub_airflow_plugin.entities.Urn
context['ti'].task.inlets = self.inlets
context['ti'].task.outlets = self.outlets
def _get_lineage(self):
# Do some processing to get inlets/outlets
return inlets, outlets
If you override the pre_execute and post_execute function, ensure they include the @prepare_lineage and @apply_lineage decorators respectively. Reference the Airflow docs for more details.
Custom Extractors
Note: these are only supported in the v2 plugin.
You can also create a custom extractor to extract lineage from any operator. This is useful if you're using a built-in Airflow operator for which we don't support automatic lineage extraction.
See this example PR which adds a custom extractor for the BigQueryInsertJobOperator operator.
Cleanup obsolete pipelines and tasks from Datahub
There might be a case where the DAGs are removed from the Airflow but the corresponding pipelines and tasks are still there in the Datahub, let's call such pipelines ans tasks, obsolete pipelines and tasks
Following are the steps to cleanup them from the datahub:
- create a DAG named
Datahub_Cleanup, i.e.
from datetime import datetime
from airflow import DAG
from airflow.operators.bash import BashOperator
from datahub_airflow_plugin.entities import Dataset, Urn
with DAG(
"Datahub_Cleanup",
start_date=datetime(2024, 1, 1),
schedule_interval=None,
catchup=False,
) as dag:
task = BashOperator(
task_id="cleanup_obsolete_data",
dag=dag,
bash_command="echo 'cleaning up the obsolete data from datahub'",
)
- ingest this DAG, and it will remove all the obsolete pipelines and tasks from the Datahub based on the
clustervalue set in theairflow.cfg
Get all dataJobs associated with a dataFlow
If you are looking to find all tasks (aka DataJobs) that belong to a specific pipeline (aka DataFlow), you can use the following GraphQL query:
query {
dataFlow(urn: "urn:li:dataFlow:(airflow,db_etl,prod)") {
childJobs: relationships(
input: { types: ["IsPartOf"], direction: INCOMING, start: 0, count: 100 }
) {
total
relationships {
entity {
... on DataJob {
urn
}
}
}
}
}
}
Emit Lineage Directly
If you can't use the plugin or annotate inlets/outlets, you can also emit lineage using the DatahubEmitterOperator.
Reference lineage_emission_dag.py for a full example.
In order to use this example, you must first configure the Datahub hook. Like in ingestion, we support a Datahub REST hook and a Kafka-based hook. See the plugin configuration for examples.
Debugging
Missing lineage
If you're not seeing lineage in DataHub, check the following:
- Validate that the plugin is loaded in Airflow. Go to Admin -> Plugins and check that the DataHub plugin is listed.
- With the v2 plugin, it should also print a log line like
INFO [datahub_airflow_plugin.datahub_listener] DataHub plugin v2 using DataHubRestEmitter: configured to talk to <datahub_url>during Airflow startup, and theairflow pluginscommand should listdatahub_pluginwith a listener enabled. - If using the v2 plugin's automatic lineage, ensure that the
enable_extractorsconfig is set to true and that automatic lineage is supported for your operator. - If using manual lineage annotation, ensure that you're using the
datahub_airflow_plugin.entities.Datasetordatahub_airflow_plugin.entities.Urnclasses for your inlets and outlets.
Incorrect URLs
If your URLs aren't being generated correctly (usually they'll start with http://localhost:8080 instead of the correct hostname), you may need to set the webserver base_url config.
[webserver]
base_url = http://airflow.mycorp.example.com
TypeError ... missing 3 required positional arguments
If you see errors like the following with the v2 plugin:
ERROR - on_task_instance_success() missing 3 required positional arguments: 'previous_state', 'task_instance', and 'session'
Traceback (most recent call last):
File "/home/airflow/.local/lib/python3.8/site-packages/datahub_airflow_plugin/datahub_listener.py", line 124, in wrapper
f(*args, **kwargs)
TypeError: on_task_instance_success() missing 3 required positional arguments: 'previous_state', 'task_instance', and 'session'
The solution is to upgrade acryl-datahub-airflow-plugin>=0.12.0.4 or upgrade pluggy>=1.2.0. See this PR for details.
Compatibility
We no longer officially support Airflow <2.3. However, you can use older versions of acryl-datahub-airflow-plugin with older versions of Airflow.
The first two options support Python 3.7+, and the last option supports Python 3.8+.
- Airflow 1.10.x, use DataHub plugin v1 with acryl-datahub-airflow-plugin <= 0.9.1.0.
- Airflow 2.0.x, use DataHub plugin v1 with acryl-datahub-airflow-plugin <= 0.11.0.1.
- Airflow 2.2.x, use DataHub plugin v2 with acryl-datahub-airflow-plugin <= 0.14.1.5.
DataHub also previously supported an Airflow lineage backend implementation. While the implementation is still in our codebase, it is deprecated and will be removed in a future release. Note that the lineage backend did not support automatic lineage extraction, did not capture task failures, and did not work in AWS MWAA. The documentation for the lineage backend has already been archived.
Additional references
Related Datahub videos: